I want to predict future prices for houses and apartments. To do this, I plan to build a model to predict price given latitude, longitude, and a set of features (like number of rooms, square footage, etc) and a date in the range of my data (2013 to 2016) and another model to build this forecast to current prices (2023) and future prices (2030, for example).
In this research, I will focus on the first model. The next one will be developed in the future.
To do price calculation I developed a “new” approach due to the lack of spatial features. Here I’m going to call it “KNN Spatial Boost”. I tested 5 models:
Random Forest
KNN
Neural Network
Spatial Boosted Random Forest
Spatial Boosted Neural Network
The “KNN Spatial Boost” is a boosting algorithm to improve other model’s performance in spatial data. It’s almost a feature engineering technique because it adds k-nearest neighbors (based on specific features) as features but in addition, randomizes those neighbors a little bit in the training routine to reduce the model dependency on the dataset and improve generalization.
To read more about the algorithm, visit the code repository.
Data Exploration & Data Cleaning
Here’s my initial dataset. We need to check for outliers, missing fields, and see some distributions to identify data skewness.
Our feature selection process will be based on non-null so we are going to select
created_on
property_type
lat
lon
price
surface_covered_in_m2
rooms
I would love to use floor and surface_total_in_m2 as features but they are filled for less than 10% for the dataset. In the future, the description column can be used with NLP to improve the price prediction accuracy.
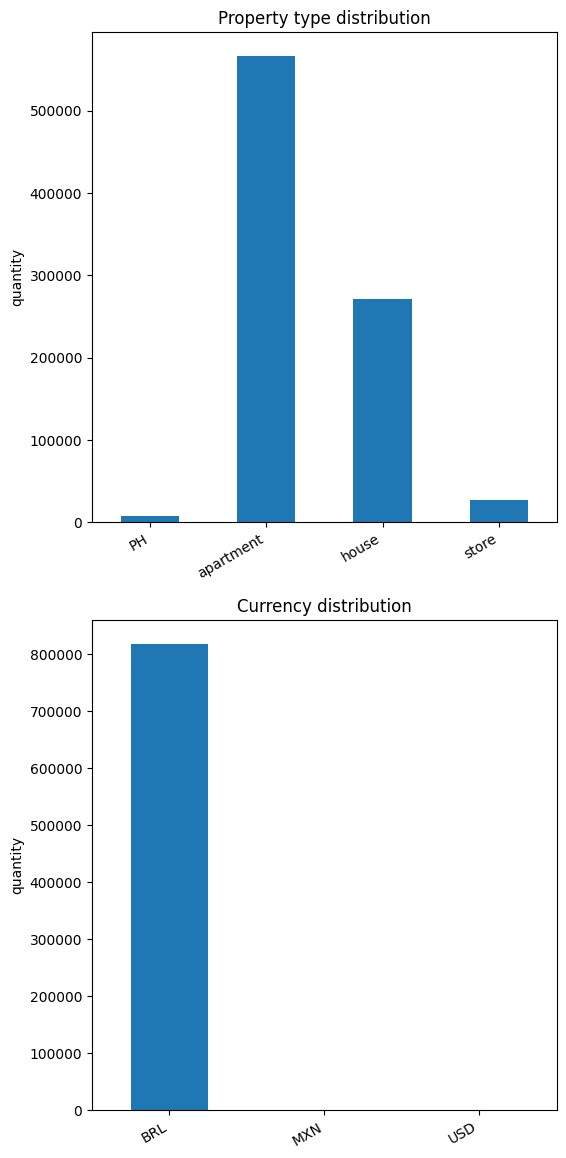
But before selecting them we need to make some other analysis. For example, which categories do we have in property_type and in currency?
/tmp/ipykernel_212015/2208899610.py:16: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
Unbalanced values can cause problems in model performance. Because of this we are going to drop PH, stores, and non-BRL rows. For continuous features, we need to do a similar analysis.
In addition to feature selection, we will convert the created_on column to ordinal and convert the property_type column to two columns like is_house and is_apartment (one-hot encoding).
/tmp/ipykernel_212015/2237906502.py:129: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
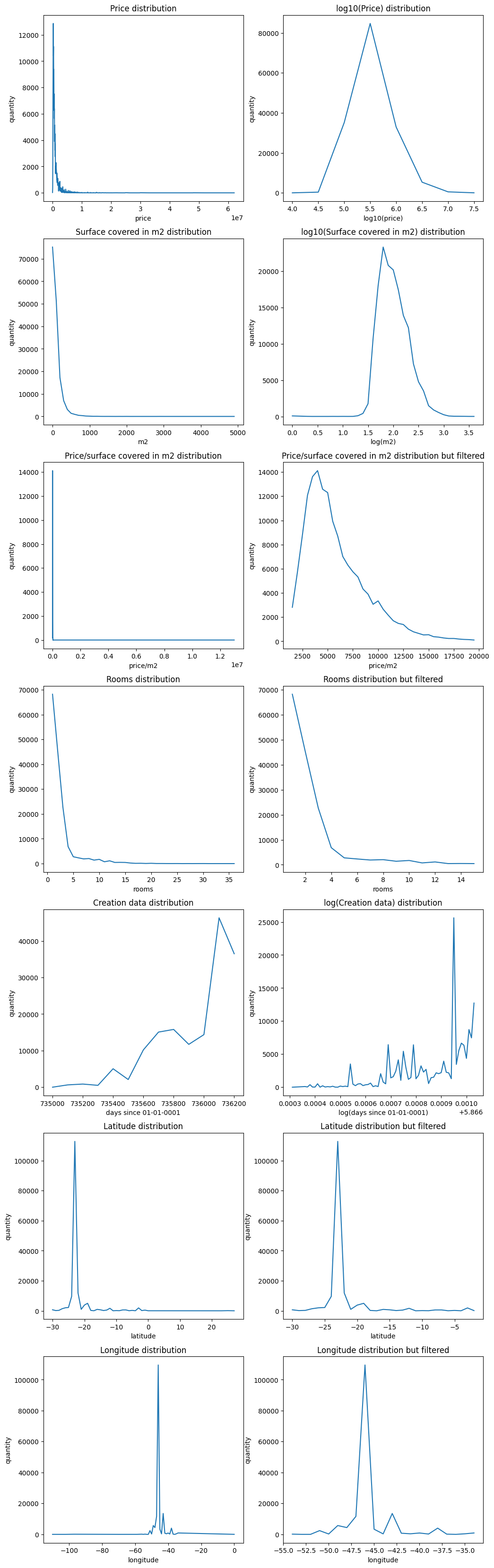
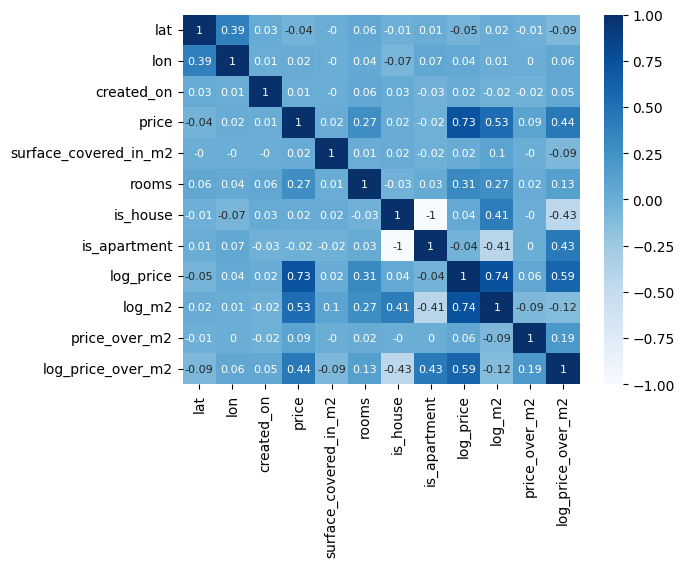
Note that some of those features are worth applying some non-linear normalization like logarithm. The price and the surface covered in m2 are obviously skewed. Rooms, creation date, price over m2, latitude, and longitude are not so much so I’m only going to apply some linear transformation and filtering to them. Before adding new features I want to see feature correlation to check if they make sense.
/home/cleto/repos/knn-spatial-boost/.venv/lib/python3.10/site-packages/pandas/core/arraylike.py:396: RuntimeWarning: divide by zero encountered in log10
result = getattr(ufunc, method)(*inputs, **kwargs)
<Axes: >
Since price and surface_covered_in_m2 are skewed I considered applying the log to them. But note that log_price and log_m2 are highly correlated (0.74). If we take a look at the price_over_m2 row in the correlation matrix, we notice that it’s not highly correlated with anything and price_over_m2 distribution is not skewed. Because of this, we are going to use it as the target column!
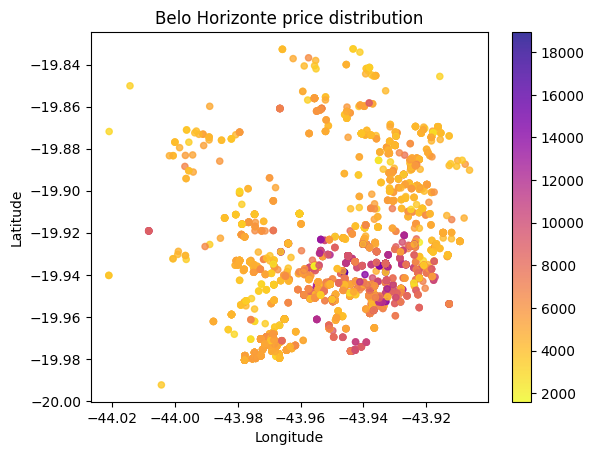
Here’s a geographical view of the data. For future comparison, we are going to “zoom in” Belo Horizonte (BH), which is a big city, filter to only apartments with 1 room. I used logarithm in the price to show colors in a smoother way.
Even with the validation dataset, we want to make some sanity checks after the training. To do it so, we built this function which evaluates the model with specific features. It’s a curried function because there are some standardized checks to apply to all models.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
/tmp/ipykernel_212015/1983228620.py:73: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
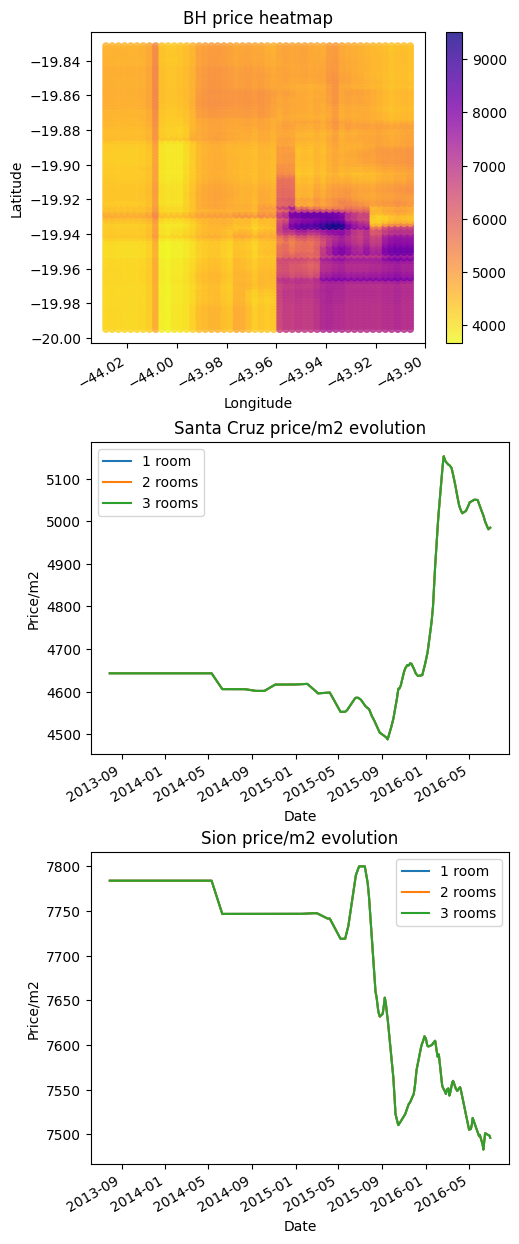
Even with the high score, the model behavior is absolutely bad.
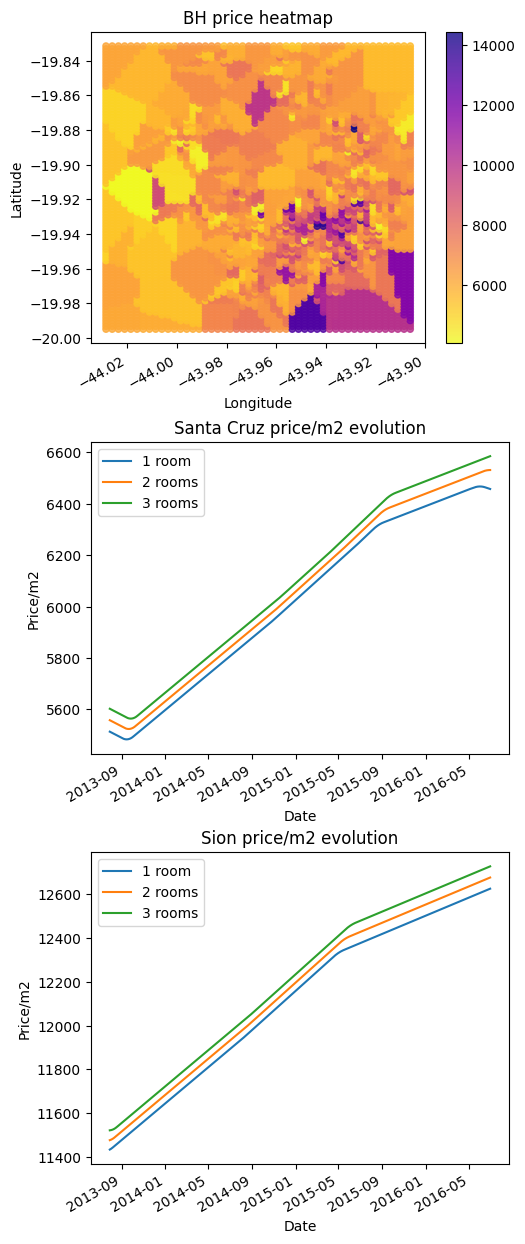
BH price heatmap: The model struggled to learn information from coordinates and built rectangular patterns. To get a more precise rectangular segmentation we need to increase max_depth and n_estimators to allow the model to store more information about the coordinates.
Price evolution: In both plots, the model cannot see the price difference between 1, 2, and 3 rooms. In real life every location got more expensive from 2013 to 2016 but for the model, the price doesn’t go up.
I believe it happened because of three reasons:
Lack of generalization capabilities in the RF model;
Lack of data;
RF can learn a limited amount of information given max_depth and n_estimators. To increase it is necessary to raise max_depth and n_estimators. Unfortunately, it will increase the model size (which currently is 127 MB), increase time to train, increase time to inference, increase RAM usage, and can overfit the model.
Going beyond this point is not worth it. It makes RF not suitable for geospatial data with only coordinates.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
/tmp/ipykernel_212015/1983228620.py:73: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
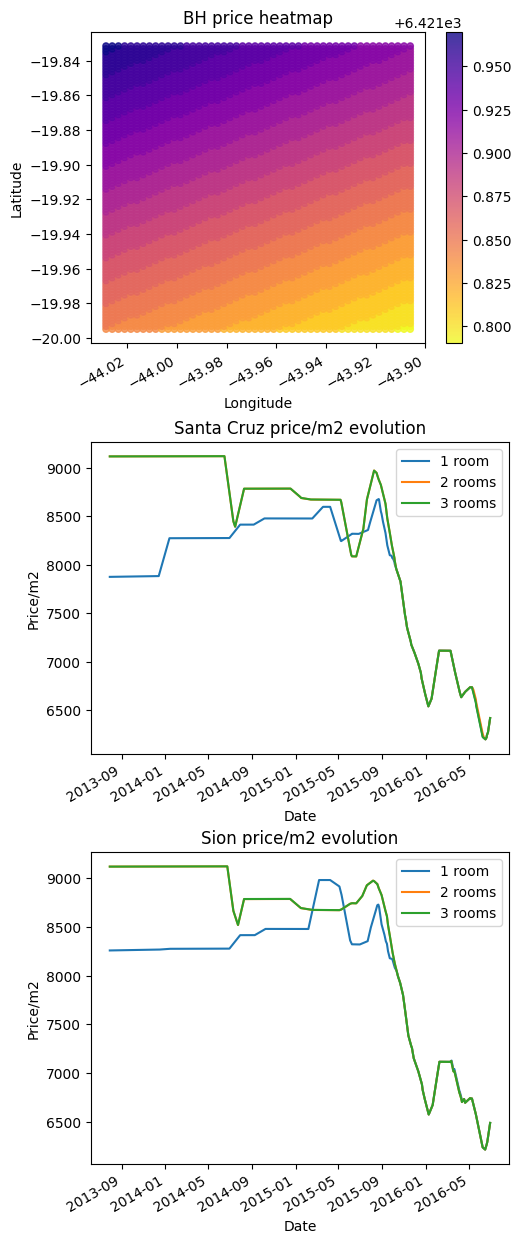
Low score and bad model behavior.
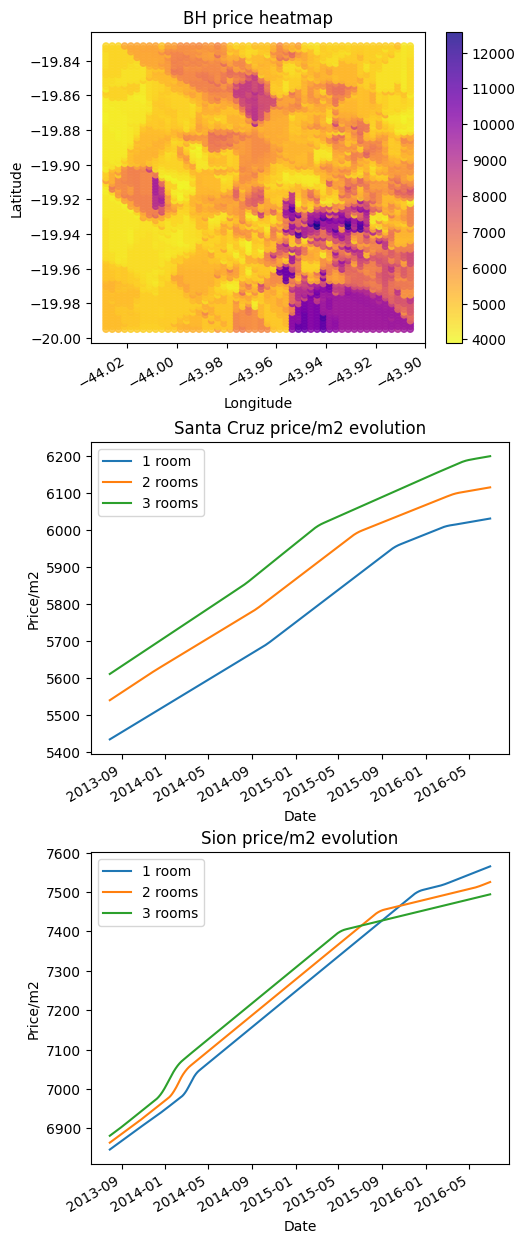
BH price heatmap: The model struggled to learn information from coordinates (maybe because of other features that are not geospatial coordinates) and built a random surface. Even lowering our expectations and allowing for a “low-resolution heatmap” the price should be higher at the bottom of the figure, not lower.
Price evolution: In both plots, the model cannot see too much price difference between 1, 2 and 3 rooms. The price is the same for a well-known expensive location and a well-known cheap location. In real life, every location got more expensive from 2013 to 2016 but for the model, the price doesn’t go up. Instead of it, the price goes up and down “randomly”.
This model can “learn” a lot of information but cannot learn the patterns from them.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
/tmp/ipykernel_341749/1983228620.py:73: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
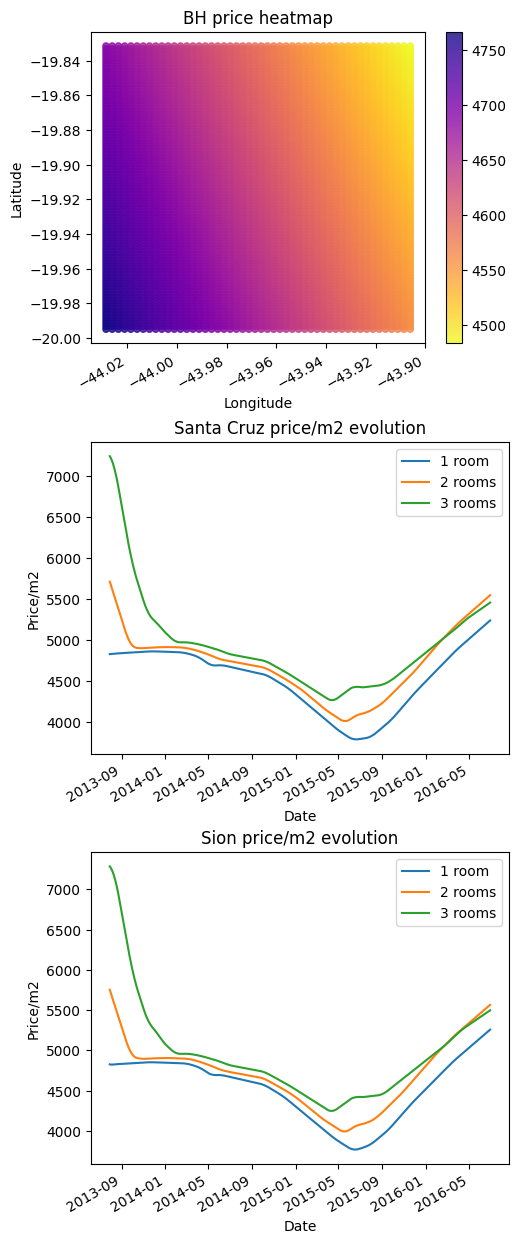
Low score and bad model behavior.
BH price heatmap: The model struggled to learn information from coordinates and built a “random” surface. Even lowering our expectations and allowing a “low-resolution heatmap” the price should be higher on the right of the figure, not left.
Price evolution: The model ordered rooms almost OK but there’s not much price difference between 1, 2 and 3 rooms. The price is the same for a well-known expensive location and a well-known cheap location. In real life, every location got more expensive from 2013 to 2016 but for the model, the price goes down.
To allow the neural network to learn the patterns from the coordinates we will need a lot more parameters and running time.
PS: I attempted to run a neural network with the architecture 6-2000-2000-2000-1 on my notebook’s graphics card, but I did not see any improvement in the score even with more than 1 hour of train time.
Spatial Boosted Random Forest
Here’s where things got interesting. Since the “KKN Spatial Booster” increases model spatial awareness we can get a lot better behaviour.
from knn_spatial_boost.core import KNNSpatialBooster
/tmp/ipykernel_341749/1983228620.py:73: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
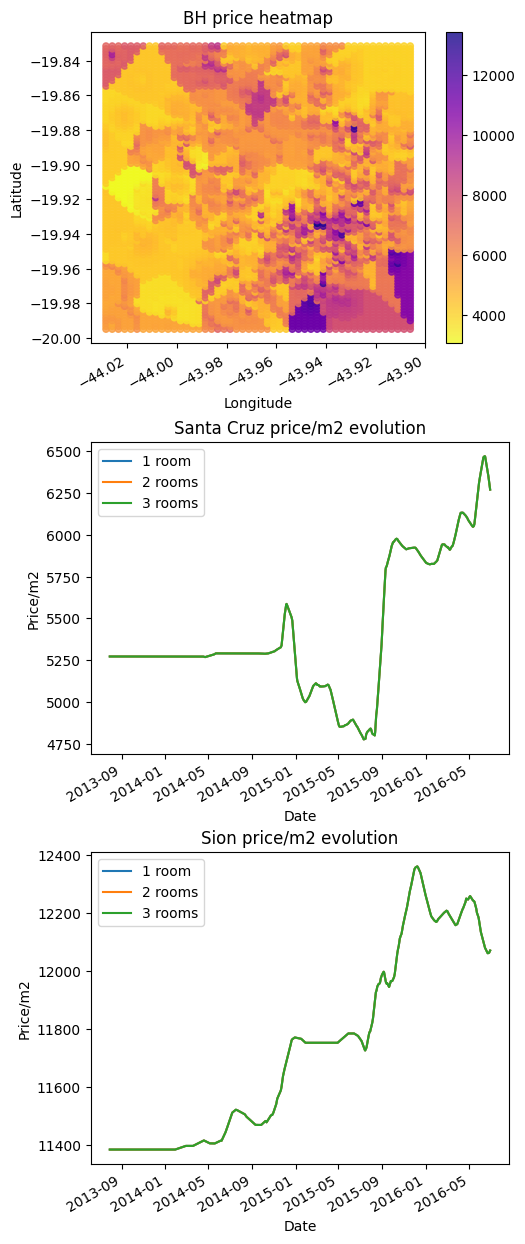
Better model behavior but lower score.
BH price heatmap: Now we have a picture that looks like a city and not a “random” surface. The more expensive region of the city is darker, which is a great sign.
Price evolution: In both plots, the model cannot see the price difference between 1, 2, and 3 rooms. In real life every location got more expensive from 2013 to 2016 but for the model, the price doesn’t go up. Instead of it, the price goes up and down “randomly”.
Even with the spatial boost, looks like RF is not the right algorithm to deal with this problem because of its lack of generalization capabilities. It’s a calculation problem and all NNs do are calculations. That’s why we are going to try it with the spatial booster.
Running loop #0
Iteration 1, loss = 0.01076201
Validation score: 0.639482
Iteration 2, loss = 0.00505485
Validation score: 0.646830
Iteration 3, loss = 0.00502750
Validation score: 0.606791
Iteration 4, loss = 0.00499496
Validation score: 0.594461
Iteration 5, loss = 0.00496672
Validation score: 0.654910
Iteration 6, loss = 0.00493094
Validation score: 0.651485
Iteration 7, loss = 0.00491670
Validation score: 0.631484
Iteration 8, loss = 0.00488778
Validation score: 0.656580
Iteration 9, loss = 0.00488642
Validation score: 0.640114
Iteration 10, loss = 0.00487413
Validation score: 0.654056
Running loop #1
Iteration 1, loss = 0.00492030
Validation score: 0.657268
Iteration 2, loss = 0.00489820
Validation score: 0.659917
Iteration 3, loss = 0.00490151
Validation score: 0.657331
Iteration 4, loss = 0.00489341
Validation score: 0.662173
Iteration 5, loss = 0.00487561
Validation score: 0.660516
Iteration 6, loss = 0.00487458
Validation score: 0.653273
Iteration 7, loss = 0.00486312
Validation score: 0.663242
Iteration 8, loss = 0.00486511
Validation score: 0.656660
Iteration 9, loss = 0.00485934
Validation score: 0.661999
Iteration 10, loss = 0.00484734
Validation score: 0.650012
Running loop #2
Iteration 1, loss = 0.00484281
Validation score: 0.658492
Iteration 2, loss = 0.00483870
Validation score: 0.660877
Iteration 3, loss = 0.00483310
Validation score: 0.661852
Iteration 4, loss = 0.00482470
Validation score: 0.661438
Iteration 5, loss = 0.00481553
Validation score: 0.651800
Iteration 6, loss = 0.00481803
Validation score: 0.646303
Iteration 7, loss = 0.00480763
Validation score: 0.662768
Iteration 8, loss = 0.00480969
Validation score: 0.663732
Iteration 9, loss = 0.00480441
Validation score: 0.660551
Iteration 10, loss = 0.00479137
Validation score: 0.660748
Running loop #3
Iteration 1, loss = 0.00482647
Validation score: 0.657868
Iteration 2, loss = 0.00483086
Validation score: 0.658173
Iteration 3, loss = 0.00482533
Validation score: 0.661644
Iteration 4, loss = 0.00481965
Validation score: 0.660866
Iteration 5, loss = 0.00481187
Validation score: 0.654417
Iteration 6, loss = 0.00481857
Validation score: 0.648055
Iteration 7, loss = 0.00481070
Validation score: 0.659433
Iteration 8, loss = 0.00481106
Validation score: 0.660187
Iteration 9, loss = 0.00480457
Validation score: 0.660062
Iteration 10, loss = 0.00479852
Validation score: 0.657204
Running loop #4
Iteration 1, loss = 0.00477730
Validation score: 0.647587
Iteration 2, loss = 0.00477892
Validation score: 0.657816
Iteration 3, loss = 0.00477693
Validation score: 0.653692
Iteration 4, loss = 0.00477174
Validation score: 0.646146
Iteration 5, loss = 0.00476712
Validation score: 0.646889
Iteration 6, loss = 0.00477756
Validation score: 0.657485
Iteration 7, loss = 0.00476419
Validation score: 0.657585
Iteration 8, loss = 0.00476931
Validation score: 0.659595
Iteration 9, loss = 0.00476752
Validation score: 0.658798
Validation score did not improve more than tol=0.000000 for 20 consecutive epochs. Stopping.
Running loop #5
Iteration 1, loss = 0.00478566
Validation score: 0.654872
Validation score did not improve more than tol=0.000000 for 20 consecutive epochs. Stopping.
Running loop #6
Iteration 1, loss = 0.00476722
Validation score: 0.659148
Validation score did not improve more than tol=0.000000 for 20 consecutive epochs. Stopping.
Running loop #7
Iteration 1, loss = 0.00477244
Validation score: 0.645208
Validation score did not improve more than tol=0.000000 for 20 consecutive epochs. Stopping.
Running loop #8
Iteration 1, loss = 0.00477162
Validation score: 0.656917
Validation score did not improve more than tol=0.000000 for 20 consecutive epochs. Stopping.
Running loop #9
Iteration 1, loss = 0.00475579
Validation score: 0.649134
Validation score did not improve more than tol=0.000000 for 20 consecutive epochs. Stopping.
/home/cleto/repos/knn-spatial-boost/.venv/lib/python3.10/site-packages/sklearn/neural_network/_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (10) reached and the optimization hasn't converged yet.
warnings.warn(
/home/cleto/repos/knn-spatial-boost/.venv/lib/python3.10/site-packages/sklearn/neural_network/_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (10) reached and the optimization hasn't converged yet.
warnings.warn(
/home/cleto/repos/knn-spatial-boost/.venv/lib/python3.10/site-packages/sklearn/neural_network/_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (10) reached and the optimization hasn't converged yet.
warnings.warn(
/home/cleto/repos/knn-spatial-boost/.venv/lib/python3.10/site-packages/sklearn/neural_network/_multilayer_perceptron.py:691: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (10) reached and the optimization hasn't converged yet.
warnings.warn(
boosted_nn.score(X_valid, y_valid)
0.6188857129459122
sanity_checks(boosted_nn)
/tmp/ipykernel_341749/1983228620.py:73: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
Best model behavior but low score.
BH price heatmap: Now we have a picture that looks like a city and not a “random” surface. The more expensive region of the city is darker, which is a great sign.
Price evolution: Curves correct order (3 rooms are more expensive than 2 rooms). Correct behavior over time since the price goes up.
Everything looks good but the scores in both training and validation datasets are poor. Note that we decided to use only the first neighbor and maybe there’s not enough context to the model to calculate a final price. To increase the number of neighbors we need to increase the NN size because it cannot handle this amount of information.
When trying to increase the number of neighbors and the number of neurons in each layer my CPU started struggling. The SciKit Learn implementation of NN is CPU-only so I tried Tensorflow and Keras to use my GPU.
I tested a lot of neighbor quantities with the 2000-2000-2000-1 architecture (and built a table with training score, validation score, etc, but I lost it) and figured out that 4 is the ideal number of neighbors for that amount of neurons and layers.
Almost correct order and arguable price evolution and price difference between places
RF had the best score but with a little bit more investigation we see a bad geospatial generalization and no price difference when adding more rooms. It seems to overfit but due to a lack of data and not to a model inability. We need more spatial features like distance to the nearest city center, hospital, school, public transportation, etc.
KNN had the best time to train but struggled with all other evaluation criteria.
NN seems to underfit. It’s expected given the time to train and the complexity of understanding price fluctuation given only coordinates. It’s possible to fit a NN with this data but only with a lot more time to train and a bigger architecture.
Instead of adding spatial features like distance to the nearest city center, I decided to use KNN to increase model spatial awareness by adding neighbors as features. In addition, I implemented neighbor randomness to improve model generalization.
Spatial Boosted RF had better geospatial generalization but again seems to overfit due to lack of data.
As NNs have greater generalization capacity, in the end, Spatial Boosted NN was the model that best managed to learn the patterns even with little data. It had the best qualitative performance even scoring worse than other models. The bigger version of it managed to score closer to the RF (0.719).
Improvements & Ideas
I believe we can encode spatial data in better ways. As we can see here, we can use coordinates as discrete cells, calculate embeddings for them, and use them in a transformer. Maybe in the future, I will try to reproduce this technique for this problem.
About this research
Generate a GIF to show price evolution through time.
Add an online demo for portfolio purposes.
description column can be used with NLP.
About the method
Identify the way this method affects the base model (needs more tuning?).
Try another dataset to figure out which kind of problem suits better with the technique.